P. J. Smith, "Voice Conferencing over IP Networks ", Masters Thesis, McGill University, January, 2002.
Traditional telephone conferencing has been accomplished by way of a centralized conference bridge. An Internet Protocol (IP)-based conference bridge is subject to speech distortions and substantial computational demands due to the tandem arrangement of high compression speech codecs. Decentralized architectures avoid the speech distortions and delay, but lack strong control and have a key dependence on silence suppression for endpoint scalability. One solution is to use centralized speaker selection and forwarding, and decentralized decoding and mixing. This approach eliminates the problem of tandem encodings and maintains tight control, thereby improving the speech quality and scalability of the conference. This thesis considers design options and solutions for this model, and evaluates performance through live conferences with real conferees. Conferees found the speaker selection of the new conference model to be transparent, and strongly preferred the resulting speech quality to that of a centralized IP-based conference bridge.
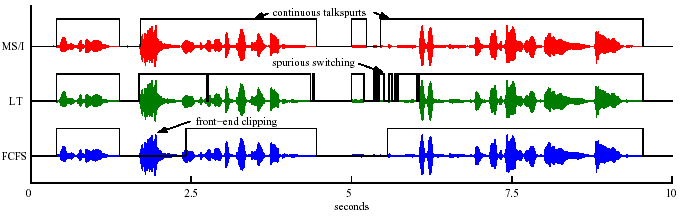
The following files are based on a four-person conversation (three male, one female) recorded over a PC-based conferencing test bed. The PCs were running Linux, and (the) Robust Audio Tool (RAT) version 4.10 was used as the conference endpoints. The conversation was approximately 10 minutes in length, during which the four participants were engaged in a problem solving task based on the TV game show Family Feud. Each conferee's voice was recorded and stored separately as 16-bit 8 kHz WAVE files, then were synchronized and searched for the most active portions. The most active 10 second segment had a state distribution of 14.2%, 30.6%, 35%, 11.4%, and 8.8 % for silence, single-talk, double-talk, triple-talk, and quadruple-talk, respectively, and was chosen for the following audio demonstration. The conference output, as would be heard from a fifth "listener-only" conferee, was obtained by inputting the recorded files to a program which could simulate the effects of a conventional conference bridge with tandemed G.729A connections, or those of a Tandem-Free Operation conference with centralized speaker selection and decentralized mixing. Speaker selection could be performed over 20 ms intervals using one of the First-Come-First-Served (FCFS), Loudest Talker (LT) or Multi-Speaker/Interrupter (MS/I) algorithms. The selected 10 second segment begins after the female conferee has finished reading the question, "Name something that comes in a bag."
These files show the difference in speech quality between a conventional VoIP conference bridge using G.729A, and a Tandem-Free Operation conference with two selected speakers.
Notes:
Additional files with other configurations:
Speaker Selection Algorithms
These files show the difference in speech quality as a function of speaker selection algorithm. Two out of four conferees were selected for output over 20 ms intervals. The selected speech of the primary speaker, i.e., the female speaker, as selected by each of the three algorithms, is shown in the following figure (MS/I is the Multi-Speaker/Interrupter algorithm; LT is the Loudest Talker selection algorithm; FCFS is the First-Come-First-Served algorithm).